AI年代:給AI裝耳朵 識聽識唱識奏樂 中大教授研音頻AI 冀像人類理解聲音


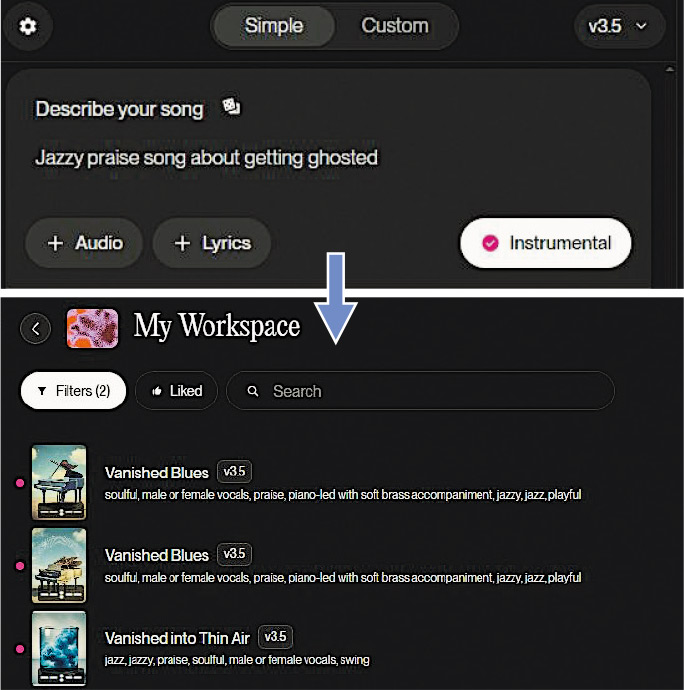
【明報專訊】生成式人工智能逐漸融入日常生活,通過文字與人對話的人工智能(AI)大模型ChatGPT、DeepSeek風靡全球,能生成圖像的midjourney、生成影片的SORA紅極一時。音樂也有自己的「ChatGPT」,SUNO、Mureka等AI能把用戶輸入的一段文字描述轉化成一段音樂,聲稱能讓每個普通人都成為作曲家。香港中文大學電子工程學系助理教授孔秋強表示,雖然現時AI作曲遠未達到專業人士水平,但人工智能在音頻相關部分領域的應用已經相當成熟,有的應用在社交網絡隨處可見。
作為中大數字信號處理實驗室(DSP Lab)的一員,孔秋強目前從事音頻AI相關研究,其中一個範疇是音頻理解,孔秋強形容是「給一個大語言模型裝上耳朵」,目標是讓AI能像人類一樣理解聲音,包括對音頻標籤、分類,例如串流平台向用戶推薦感興趣的音樂;音頻事件監測,例如判斷公共場所發生事故、長者在家出現意外等;音源分離,例如將一首歌的人聲和伴奏分開。
語音合成技術最普及 人聲成熟
在音頻生成領域,孔秋強表示,針對業界的應用場景可以分成語音、音樂、音效3種不同任務;其中,AI生成音效過去探索相對較少,但重要性很高,特別是對多媒體內容創作。目前市面上應用最廣泛的是語音合成(Text to Speech)技術。該技術由來已久,但近年在AI的加持下效果大幅提升,聲調抑揚頓挫、拆句自然流暢。孔秋強表示,電腦合成出來的「人聲」音色愈來愈豐富、情感愈來愈多樣、語速愈來愈快。他說,在短片平台流行的當下,許多影片中的旁白其實並非真人配音,而是由AI合成,目前公眾知道的幾乎所有大型互聯網企業都投入了大量資源從事相關開發。
英國AI企業DeepMind在2016年推出了第一個能夠生成音樂波形的模型WaveNet,之後陸續出現了OpenAI的Jukebox、Google的MusicLM等項目。孔秋強表示,音樂AI目前處於初級階段,雖然實現了從文本指令生成音頻,但AI生成出來的音樂並不具有美學上的意義。孔秋強表示,將SUNO等音樂AI稱作「音樂界的ChatGPT」,是因為不同媒介的生成式AI背後的技術方案均基於變換器(Transformer)模型。用戶所見,ChatGPT、DeepSeek等應用的回答是逐字逐字生成的,音樂AI的歌曲則是逐幀逐幀生成的,都顯示出變換器模型的特點。
音樂AI尚欠美感 訓練數據制約發展
2020年發表的擴散模型(Diffusion Model)成為AI領域里程碑,對音樂AI也有極大推動。孔秋強表示,音頻可以轉換成頻譜圖(Spectrogram),音樂生成轉換為圖像生成,而擴散模型在圖像生成方面有出色表現。2022年發表的SUNO應用了擴散模型,可以生成音質更好的音頻;轉換模型在長上下文相關性的優勢,讓生成出來的音樂結構較為完整。孔秋強認為,擴散模型問世至今,在下一個根本性突破出現之前,訓練數據是目前制約AI發展的瓶頸。對於構建音頻生成AI,關鍵是平行數據。平行數據指音頻及其描述,包括長度、速度、節拍、風格、樂器、歌手、歌詞等,描述愈詳細平行數據質量愈高,但這些內容依賴人類貢獻。
AI令音頻變琴譜 未來或「反哺」作訓練
孔秋強加入中大前曾供職於北京的字節跳動人工智能實驗室,其主導的鋼琴轉譜(Transcription)項目「GiantMIDI-Piano」用AI將逾萬段鋼琴獨奏音頻,轉為並非聲音本身而是一系列演奏指令的MIDI文件;AI除了音高、節奏、強弱等基礎信息,還能夠分析出琴鍵、踏板的狀態,更忠實還原音樂家的臨場演奏效果。除了偶爾在高級飯店出現的自動演奏鋼琴,孔秋強表示,鋼琴轉譜技術目前最大的用途是音樂教育,一些手機應用程式能檢測初學者的演奏是否正確,用AI教人彈琴。另外,AI提高轉譜的效率,未來可能將世界上現存的所有歌曲變為MIDI文件,「反哺」給AI作為訓練數據,提升AI的性能。
明報記者



灣區熱搜:深圳焚化爐設園區解民懼 專家倡借鑑 垃圾全程閉環數據透明 着力「鄰避」到「鄰愛」
【明報專訊】垃圾處理一直是香港重要議題,「走塑令」推行一年有多,垃圾徵費卻也暫緩逾年。環境及生態局長謝展寰早前稱,現時垃圾量已差不多達到垃圾... 詳情
灣區熱搜:煙囪頂設咖啡吧 360度觀景成網紅點
【明報專訊】南山能源生態園位於深圳前海自貿區,建築設計融合自然景觀,打破傳統垃圾焚燒場的刻板印象。主廠房採用海浪造型的鋼架結構,煙囪被塑為馬... 詳情